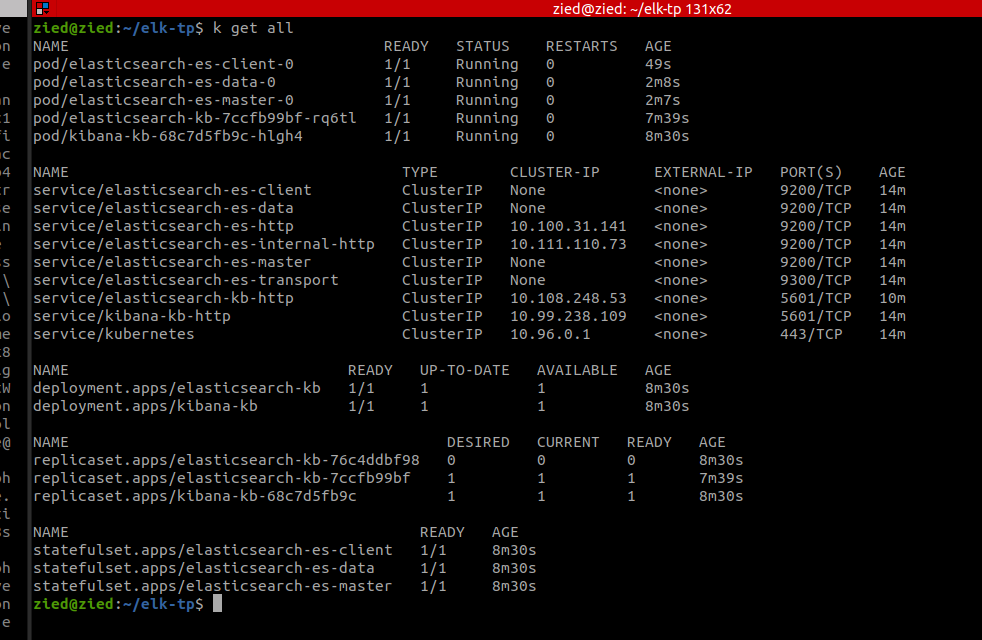
Formation DevOps | Formation kubernetes : 10 - Deployer la stack ELK (Elasticseach,Fluentd,logstash,kibana)
![]()
Superviser votre site web et vos applications avec ELK !! : Deployer la stack ELK ( Elasticseach, Fluentd ,Logstash , Kibana) sur EKS
Processus du traitement d’une donnée :
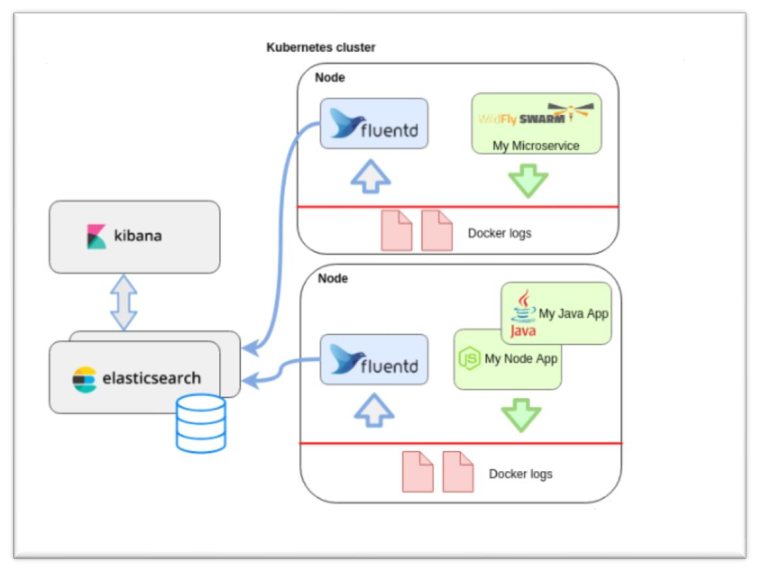
La stack logging est composé de :
• Elasticsearch : Stockage des logs .
• Kibana : Représentation des logs .
• Logstash : Analyse de logs .
• Fluented : Collecteur de logs
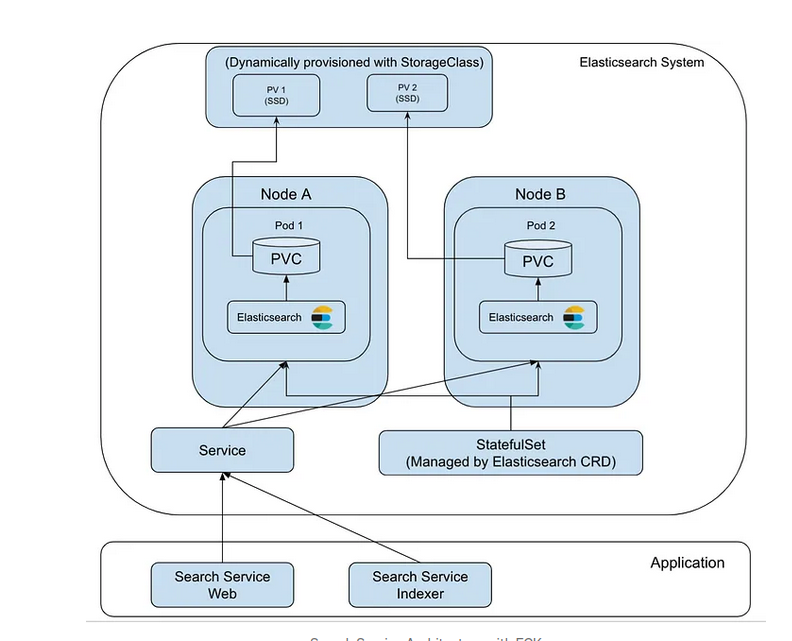
Le Elasticsearch Operator qui est également connu sous le nom Elastic Cloud on Kubernetes(ECK) de Kubernetes Operator pour orchestrer des applications Elastic ( Elasticsearch, Kibana, APM Server, Enterprise Search, Beats, Elastic Agentet Elastic Maps Server) sur Kubernetes.
Il s’appuie sur un ensemble de définitions de ressources personnalisées (CRD) pour définir de manière déclarative la manière dont chaque application est déployée. ECK simplifie le déploiement de l’ensemble de la pile Elastic sur Kubernetes, en nous donnant des outils pour automatiser et rationaliser les opérations critiques.
Il se concentre sur la rationalisation de toutes ces opérations critiques telles que, Managing and monitoring multiple clusters, Upgrading to new stack versions with ease, Scaling cluster capacity up and down, Changing cluster configuration, Dynamically scaling local storage (includes Elastic Local Volume, a local storage driver), Scheduling backupsetc. Dans cet article, je vais discuter du déploiement d’un cluster Elasticsearch évolutif sur Kubernetes à l’aide d’ECK.
Tous les déploiements liés à ce post disponibles dans gitlab . Veuillez cloner le dépôt et continuer la publication.
git clone https://gitlab.com/Itgalaxy1/k8s-formations/elk
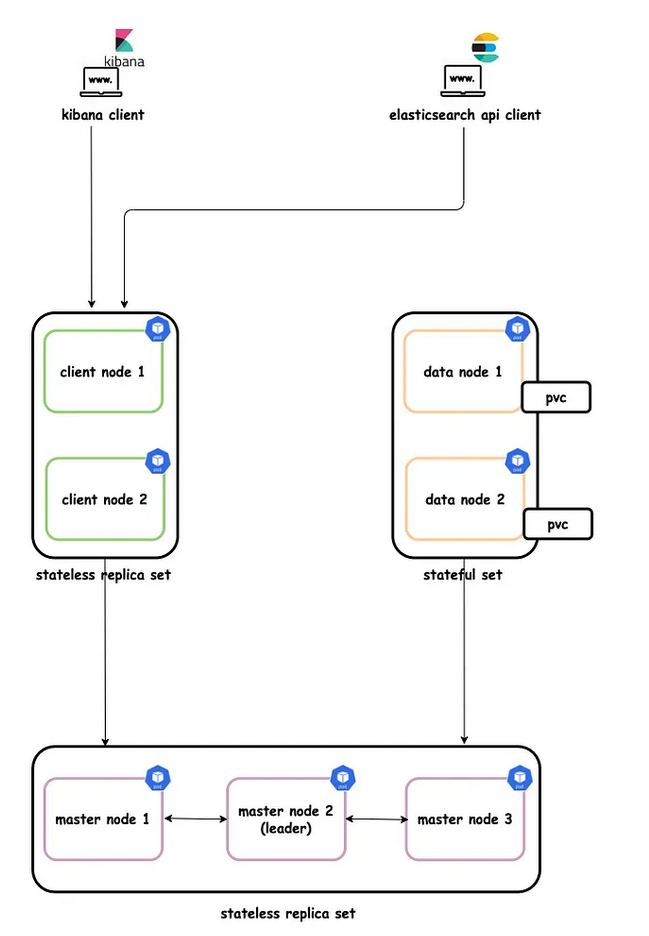
Architecture de cluster
Le cluster Elasticseach contient trois types de nœuds : Master nodes(gère la gestion et la configuration à l’échelle du cluster), Data nodes(stocke les données et exécute la recherche d’opérations liées aux données) et Client nodes(transmet les requêtes du cluster au nœud maître et les requêtes liées aux données aux nœuds de données).
Ces nœuds sont déployés en tant que pods dans le cluster Kubernetes. La meilleure pratique consiste à utiliser 7 pods dans le cluster Elasticsearch 3 Master node pods, 2 Data node pods and 2 Client node pods.
La figure suivante montre l’architecture du cluster avec ces pods.
Les pods de nœuds de données sont déployés en tant que StatefulSet service headless pour fournir des identités réseau stables.
Les pods de nœud maître sont déployés en tant que ReplicaSet service headless qui facilitera la découverte automatique.
Les pods de nœuds clients sont déployés en tant que ReplicaSet service clusterIP qui permettra d’accéder aux nœuds de données pour les requêtes R/W.
Installer l’opérateur ECK
Pour déployer Elasticsearch sur Kubernetes, je dois d’abord installer l’opérateur ECK dans le cluster Kubernetes.
Il existe deux manières principales d’installer ECK dans un cluster Kubernetes :
- Installer ECK à l’aide des manifestes YAML (c’est ce qu’on va faire dans cette partie)
- Installer ECK à l’aide du Helm on va le faire dans un autre cours.
1- CustomResourceDefinitionobjets pour tous les types de ressources pris en charge (Elasticsearch, Kibana, APM Server, Enterprise Search, Beats, Elastic Agent et Elastic Maps Server). il y a un cours dedié dans le chapitre objects.
2- Namespace elastic-system pour contenir toutes les ressources de l’opérateur.
3- ServiceAccount, ClusterRole et ClusterRoleBinding pour permettre à l’opérateur de gérer les ressources dans tout le cluster.
4- ValidatingWebhookConfiguration pour valider les ressources personnalisées Elastic lors de l’admission.
5- StatefulSet, ConfigMaps dans l’espace Secretde noms pour exécuter l’application opérateur.Service lastic-system
Déployer le cluster Elasticsearch
Maintenant qu’ECK s’exécute dans le cluster Kubernets, j’ai l’ elasticsearch.k8s.elastic.co/v1 API d’accès (qui a fourni l’opérateur ECK). Je peux déployer le cluster Elasticsearch avec cette API.
Voici le déploiement du cluster Elasticsearch avec différents types de nœuds. Veuillez noter que dans le déploiement, je n’ai utilisé 1 Master node pod, 1 Data node pod and 1 Client node pod qu’à des fins de démonstration (ici, seuls 3 pods seront déployés au lieu de 7).
Pour augmenter le nombre de pods, il vous suffit d’augmenter le count dans le déploiement YAML (par exemple count: 3 dans Master, count: 2 dans Data et count:2dans Client).
kubectl apply -f elasticsearch.yaml
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch
spec:
version: 8.11.0
nodeSets:
- name: master
count: 1
config:
node.roles: master
xpack.ml.enabled: true
node.store.allow_mmap: false
- name: data
count: 1
config:
node.roles: data
xpack.ml.enabled: true
node.store.allow_mmap: false
- name: client
count: 1
config:
node.roles: data
xpack.ml.enabled: true
node.store.allow_mmap: falsel’opératuer ECK crée StatefullSet pour elasticsearch pour cela faut bien des PV,PVC dediées et des service Headless .
Pour tester que tout fonctionne il faut utiliser le kubectl port-forward elasticsearch-kb-85b96bd76b-k9rzp 5601
ça permet de tester kibana en localhost car kubectl port-forward permet de rederiger le port 5601 du pod en localhost en port 5601 c’est de la vrai magie par contre faut pas oublié le https car c’est activé pas de gestion de certificat de notre coté .
Pour la récupération de password de user elastic par default il est dans l’object secrets elasticsearch-es-elastic-user :
Faut lancer la ligne de command :
kubectl get secret elasticsearch-es-elastic-user -o go-template=’{{.data.elastic | base64decode}}’
Pareil pour elasticsearch on fait un kubectl port-forwad elasticsearch-es-master-0 9200
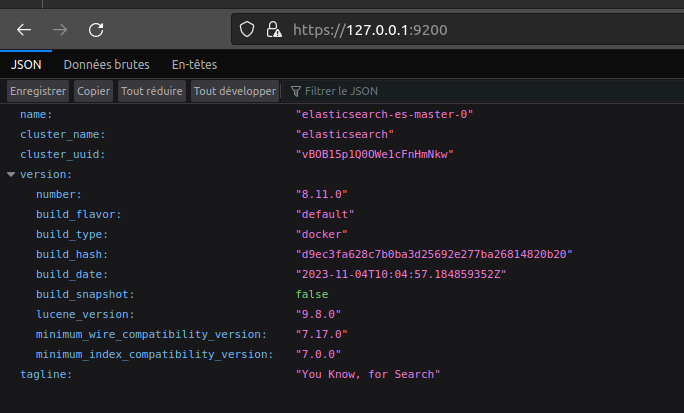
On attaque la partie récupération des logs de tous les composants qui sont présents sur notre cluster vers elasticsearch avec Fluentd.
Si vous voulez cibler un namepsace il suffit de changer le namespace .
kubectl apply -f fluented-rbac.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
namespace: default
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: defaultUtilisateurs et autorisations RBAC dans Kubernetes
Le contrôle d’accès basé sur les rôles (RBAC) est une méthode de régulation de l’accès aux ordinateurs et aux ressources réseau basée sur les rôles des utilisateurs individuels au sein d’une entreprise.
Nous pouvons utiliser le contrôle d’accès basé sur les rôles sur toutes les ressources Kubernetes supportant les accès CRUD (Create, Read, Update, Delete)
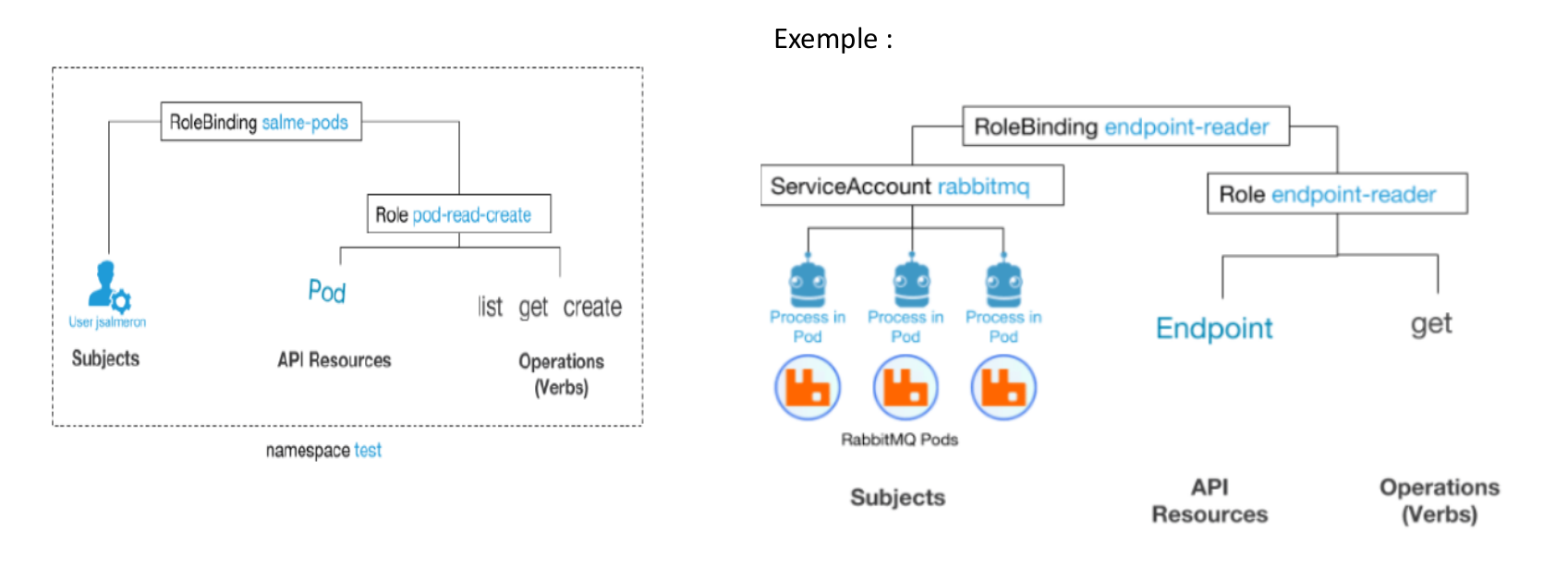
Il y a trois éléments en jeu :
Sujets : L’ensemble des utilisateurs et des processus qui souhaitent accéder a l’API Kubernetes.
Ressources : L’ensemble des objets API Kubernetes disponibles dans le cluster. Exemples : Pods, Deploiements, Services, Noeuds et PersistentVolumes, entre autres.
Verbs: L’ensemble des opérations possibles sur ces ressources .
Pour connecter ces trois types d’entités, on utilise les différents objets API RBAC disponibles dans Kubernetes :
➢Role et ClusterRole : Ce sont un ensemble de règles représentant un ensemble d’autorisations.
Un Role ne peut être utilisé que pour accorder l’accès à des ressources dans des namespaces.
Un ClusterRole peut être utilisé pour accorder les mêmes autorisations qu’un rôle, mais également pour accorder un accès à des ressources à l’échelle du cluster, des endpoints autres que des ressources.
➢Subjects: Un sujet est l’entité qui effectuera les opérations dans le cluster. Ils peuvent être des comptes d’utilisateurs, des comptes de services ou même un groupe.
➢ RoleBinding et ClusterRoleBinding : Comme son nom l’indique, il ne s’agit que de la liaison entre un sujet et un Role ou un ClusterRole.
Sujets : Utilisateurs : Ceux-ci sont globaux et s’adressent aux êtres humains ou aux processus vivant en dehors du
cluster.
ServiceAccounts : destinés aux processus intra-cluster qui se déroulent à l’intérieur des pods
kubectl apply -f fluentd-daemonset.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: default
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.16.3-debian-elasticsearch8-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-es-master"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "https"
# - name: FLUENT_UID
# value: "0"
- name: FLUENT_ELASTICSEARCH_SSL_VERIFY
value: "false"
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
value: "1Wc4D8n364Ago5nkk0vTo63Y"
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containersPour comprendre le daemontset vous pouvez regarder le chapitre sur le daemonset , il y aura un pod dans chaque node avec la spec de daemenset.
Pour résumer il y aura un pod avec l’image de fluentd-kubernetes-daemonset qui va crée un volume avec tous les directory de logs des containers /var/log ensuite transmettre tous les logs vers la db elastcisearch via son API , ensuite l’exposé avec kibana.
Parcontre si vous voulez plus de amélioration des formats de log on aura besoin de logstash avec des parser dediée pour chaque type de logs par exemple des parser pour les logs de java, nginx , apache….
Pour cette formation on va utiliser notre application nodesJs, l’image nodeJs est deja pushé sur la registry public de ItGalaxy.io faite pour vous sur AWS qui est : public.ecr.aws/ItGalaxy.io/app-nodejs-elk:v0.1.0
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodejs
spec:
selector:
matchLabels:
run: nodejs
template:
metadata:
labels:
run: nodejs
spec:
containers:
- name: nodejs
image: public.ecr.aws/d7r7x0j3/app-nodejs-elk:v0.1.0
ports:
- containerPort: 80
name: http
protocol: TCP
---
kind: Service
apiVersion: v1
metadata:
name: nodejs
spec:
selector:
run: nodejs
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
Enfin on trouve tous les logs dans kibana :
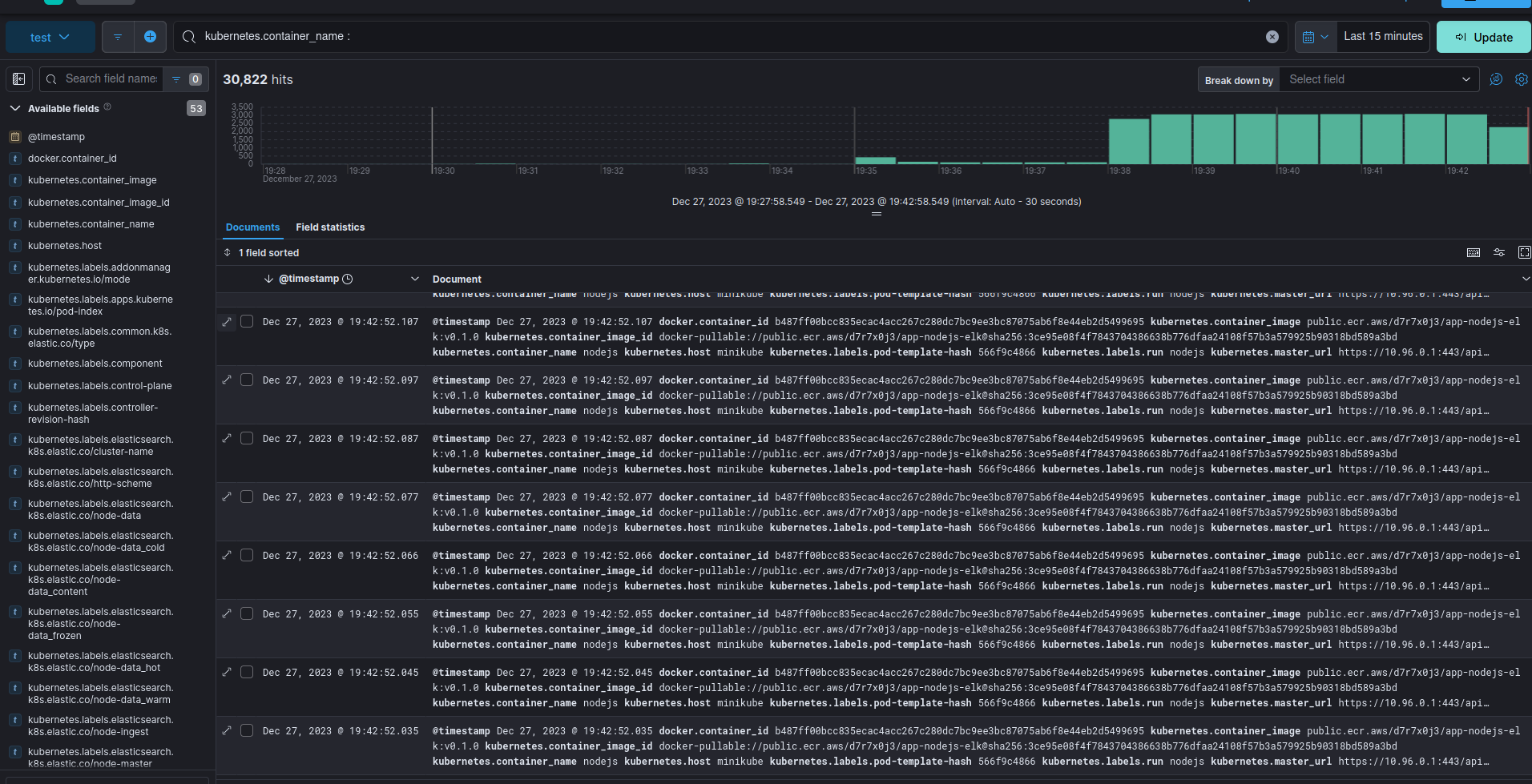
On trouve notre fameux logs de notre application ‘it works , welcom to ItGalaxy.io’
1. Nous contactez
- Description: Besoin de Formation et des Solutions cloud complètes pour vos applications
- Links:
2. Infra as a Service
- Description: Infrastructure cloud évolutive et sécurisée
- Links:
3. Projets Développeurs
- Description: Découvrez des opportunités passionnantes pour les développeurs
- Links:
4. Développeurs
- Description: Rejoignez notre communauté de développeurs
- Links:
5. Formations Complètes
- Description: Accédez à des formations professionnelles de haute qualité
- Links:
6. Marketplace
- Description: Découvrez notre place de marché de services
- Links:
7. Blogs
- Description: Découvrez nos blogs
- Links:
- comment creer une application mobile ?
- Comment monitorer un site web ?
- Command Checkout in git ?
- Comment git checkout to commit ?
- supprimer une branche git
- dockercoin
- kubernetes c est quoi
- architecture kubernetes
- Installer Gitlab Runner ?
- .gitlab-ci.yml exemples
- CI/CD
- svelte 5 vs solid
- svelte vs lit
- solidjs vs qwik
- alpine vs vue
- Plateform Freelance 2025
- Creation d’un site Web gratuitement
This website is powered by ItGalaxy.io